Unlike traditional sequential architectures like RNNs, transformers process all inputs simultaneously, allowing for greater parallelization and efficiency.
Understanding Transformer Neural Networks:
The Backbone of Modern AI
In the ever-evolving world of artificial intelligence, Transformer Neural Networks have emerged as a groundbreaking architecture, revolutionizing the way machines process and understand language, images, and even complex decision-making tasks. Introduced by Vaswani et al. in their 2017 paper, Attention Is All You Need, Transformers have paved the way for advanced AI models like GPT, BERT, and T5.
What Are Transformer Neural Networks?
Unlike traditional sequence models such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, Transformers eliminate the need for sequential data processing. Instead, they rely on a mechanism called self-attention, which allows the model to analyze all input data simultaneously, identifying relevant information without the constraints of sequential dependencies.
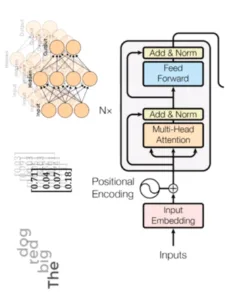
The Key Components of Transformers
Transformers consist of several essential components that work together to process and generate meaningful representations:
- Self-Attention Mechanism – Determines the importance of different elements within an input sequence, enabling the model to focus on crucial information.
- · Positional Encoding – Since Transformers do not process data sequentially, positional encoding helps maintain order and context.
- · Multi-Head Attention – Employs multiple attention mechanisms in parallel, allowing the model to understand various aspects of the data.
- · Feed-Forward Layers – Enhance the model’s ability to learn complex patterns.
- Layer Normalization – Ensures stable training by regulating the values passing through layers.
Why Transformers Matter
Transformers have revolutionized various domains, including natural language processing, computer vision, and reinforcement learning. Their ability to process large datasets efficiently and generate high-quality outputs has contributed to advancements such as:
- Chatbots & Virtual Assistants – Used in AI-powered conversational agents like Copilot and ChatGPT.
- Machine Translation – Facilitates accurate language translation with models like Google’s BERT.
- Text Summarization – Generates concise summaries for lengthy articles.
- Image Generation & Analysis – Adapts Transformer models for vision applications like DALL·E.
Transformer Neural Networks: Redefining AI’s Capabilities
Artificial intelligence has witnessed remarkable advances in recent years, and at the heart of this revolution lies Transformer Neural Networks. These powerful architectures have transformed the way machines understand language, process visual data, and make intelligent decisions. From pioneering models like GPT, BERT, and T5 to cutting-edge AI applications, Transformers continue to shape the future of deep learning.
What Sets Transformers Apart?
Traditional models such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks rely on sequential processing, meaning they handle input data step by step. While effective for some tasks, this approach becomes inefficient when dealing with large datasets or long-range dependencies.
Transformers, however, revolutionized this process by introducing self-attention and parallel computing, enabling AI to process information more efficiently while maintaining crucial context across an entire input sequence.
Key Components That Power Transformers
Transformers consist of a sophisticated yet elegant architecture designed for deep learning tasks. Here’s what makes them work:
Self-Attention Mechanism: Determines which elements of an input sequence are most relevant.
· Multi-Head Attention: Enhances representation learning by enabling multiple attention layers to process data simultaneously.
· Positional Encoding: Retains order and structure in a sequence despite the lack of recurrence.
· Feed-Forward Layers: Strengthens the model’s ability to extract meaningful patterns.
- relevance, allowing the model to focus on key information.
- Layer Normalization: Ensures stable training by regulating values across neural layers.
How Transformers Impact AI Applications
The widespread adoption of Transformers is revolutionizing diverse fields, including:
Natural Language Processing (NLP): Transformers power language models like ChatGPT, BERT, and T5, improving machine translation, sentiment analysis, and conversational AI.
📷 Computer Vision: Adapted Transformers like Vision Transformer (ViT) are reshaping image recognition, object detection, and video analysis.
📝 Text Summarization: AI-powered Transformers efficiently condense lengthy articles into concise summaries.
Scientific Computing & Drug Discovery: Transformers enhance molecular understanding, accelerating breakthroughs in medicine.
Future Prospects: Where Are Transformers Headed?
As researchers push the boundaries of artificial intelligence, Transformers remain indispensable for the next generation of AI models. Future developments aim to:
- Reduce computational costs while improving efficiency.
- Integrate multimodal learning to process text, images, and audio together.
- Enhance reasoning and problem-solving capabilities for more complex tasks.
With limitless potential and evolving architectures, Transformers continue to lead AI into uncharted territory, pushing the boundaries of machine intelligence.